1. 画像入力対応のAIチャット
皆さんは画像入力対応のAIチャットについて興味ありませんか?ありますよね?
有名なものにGPT-4Vがありますが、有償サービスのChat-GPT Plusの契約が必要となるためなかなか手を出せないという方もいるのではないでしょうか?
今回は、OSSで画像対応もしているLLaVAをWindowsマシン上に構築して遊んでみようと思います
[Chat-GPT Plus] https://openai.com/blog/chatgpt-plus
[LLaVA] https://llava-vl.github.io/
2. 検証環境
今回使用する環境は次の通りです。GPU以外はそれほど気にしなくてもよいですが、VRAMが足りないと動作しない可能性があるので注意が必要です。VRAMは12GB、できれば16GB程度は欲しいところ。
また、Windowsマシン直接だと何かと不便なのでWSL2でUbuntuを利用します。
GPUパススルーなど考えなくてもよいので便利ですね。

3. 環境構築
基本的にはWSL2のUbuntu上で次のページの手順に沿って操作します。
https://github.com/haotian-liu/LLaVA/blob/main/docs/Windows.md
Pythonの実行環境はcondaでもpyenvでもお好みのもので大丈夫です。
公式ではcondaを使用しているのでここではpyenvの手順を掲載しておきます。
condaを使用する場合(公式の手順)でも環境によっては不足しているコマンドがある場合があります。出力されるエラー、以下のpyenvでのコマンドも参考にしてみてください。
● pyenv インストール

● 必要パッケージインストール

● Python仮想環境作成

● Python仮想環境アクセス

● 必要なpipパッケージインストール
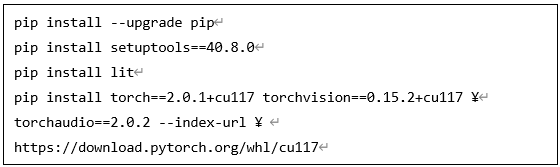
● LLaVAインストール
公式では量子化に使用するbitsandbytesをアンインストールしています。
現在、Windows (非WSL環境)では4bit、8bit量子化がサポートされていないため、
不要であればアンインストールします。

量子化:
AIモデルが使用するパラメータや演算で使用するbit数を変更することでRAMの使用量を削減できる。
ただし、推論精度は低下するため、使用する際は注意が必要となる
4. 起動する
LLaVAをUIで実行するために、コントローラ、モデルワーカー、Webサーバの3つを起動します。1つのターミナルで実行するためバックグラウンド実行しています。
● コントローラ
10000番ポートで起動します。ポート番号を変更する場合は以降のサーバ起動時に読み替えてください。

● モデルワーカー
40000番ポートで起動します。コマンドは1行で入力してください。
今回、モデルは次のものを使用します。
liuhaotian/llava-v1.5-7b (https://huggingface.co/liuhaotian/llava-v1.5-7b)
こちらのモデルはLLAMA 2 Community Licenseなので商用利用も可能ですが
月間アクティブユーザ数に応じてライセンス契約が必要となるため注意が必要です。
モデルを変更する場合は「--model-path liuhaotian/llava-v1.5-7b」の箇所を変更します。

● Webサーバ
デフォルトは7860番ポートで起動されます。

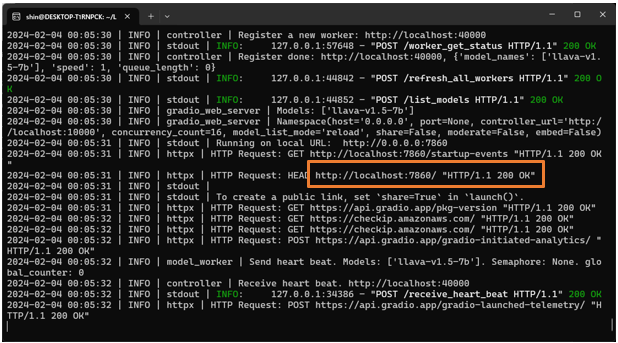
UIはブラウザで [ http://localhost:7860/ ] にアクセスします。
次のような画面が表示されたら成功です。
5. 動かしてみる
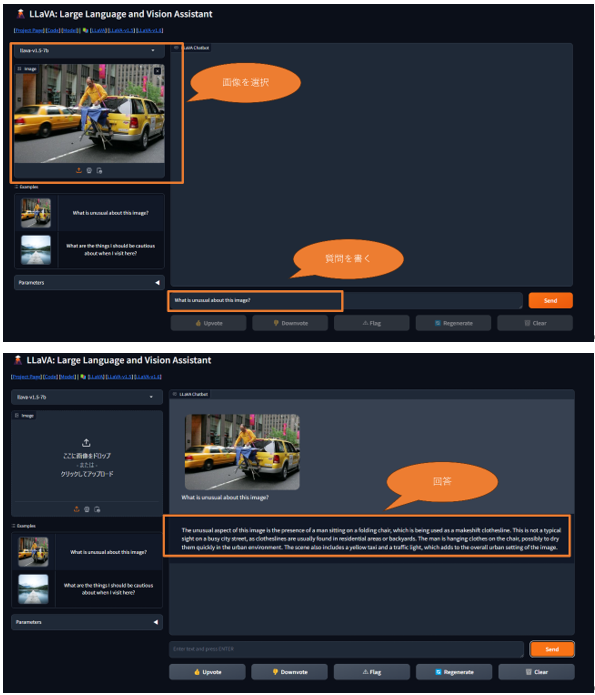
使い方は画像を選択、質問を記載してSendボタンを押すのみ。
日本語対応のモデルであれば質問を日本語で書くことで、日本語で回答をしてくれます。
6. 最後に
画像入力に対応したAIチャットを家にあるPCで動作させることができました。
画像で入力できるということで、様々なことができるようになります。
・OCRとして手書きメモのデジタル化
・クラス図からソースコード生成
・画像の要約
便利な反面、使用するモデルによっても結果が変わります。
生成されたものが必ずしも正しいというわけではないことを意識したうえで使用する必要があります。
今回、画像入力対応のLLMを紹介しましたが、画像入力こそ対応していないものの、CPUだけで動作する軽量LLMなどもあります。皆さんもぜひ自宅のPCで試してみてください。